AI 부트 캠프를 졸업했지만, 그래도 뭐 하나 따서 증명이라도 해야겠다 싶어서 TensorFlow Certificate 를 한 번 도전 해보기로 했다. 응시 비용은 진짜 엄청나게 비싸다... $100라니... 환율도 비싼데... 하아...
그래도 일단 한다!!!!

TensorFlow Certificate이니까, 튜토리얼 정도 다 공부하고 알아들으면 되겠지?? 라는 생각으로 일단 튜토리얼부터 파도록 하겠다.
구글에서 TensorFlow Tutorial이라고 검색하면 가장 처음으로 뜨는 곳이다. 들어가서 튜토리얼 하나하나 풀어보면서 블로그에 남기려고 한다. 시간은 걸려도 남겨서 기록은 해보고 싶다.
오늘도 어김없이 등장하는 목차다!!!
목차
기본 분류 : 의류 이미지 분류
- 패션 MNIST 데이터 셋 임포트하기
- 데이터 탐색
- 데이터 전처리
- 모델 구성
- 층 설정
- 모델 컴파일
- 모델 훈련
- 모델 피드
- 정확도 평가
기본 분류 : 의류 이미지 분류
TensorFlow Tutorial : https://www.tensorflow.org/tutorials?hl=ko
"감사하게도" 한국어로도 제공되고 있다.

1. 패션 MNIST 데이터 셋 임포트하기
# TensorFlow and tf.keras
import tensorflow as tf
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version___)TensorFlow와 numpy라는 라이브러리 그리고 matplotlib의 pyplot이라는 라이브러리를 임포트해서 가져온다. 마지막으로 TensorFlow의 버전도 확인해 준다.
패션 MNIST 데이터 셋은 컴퓨터 비전 분야에서는 코딩을 처음 시작할 때의 "Hello, World"와 같은 문맥이다.
패션 MNIST 데이터 셋에는 총 70,000장의 이미지가 있고, 여기서 60,000장은 학습 이미지로 사용하고 10,000장은 학습한 모델 평가 용으로 아래와 같이 사용한다.
각 이미지의 사이즈는 28x28 크기의 numpy 배열로 되어있고, 픽셀의 값은 0부터 255사이이다.
레이블은 0부터 9까지 총 10가지의 옷 클래스를 나타낸다.
| 레이블 | 클래스 |
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle Boot |
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()load.data() 함수로 데이터를 호출하면, numpy 배열을 반환하게 된다.
- train_images는 학습에 사용되는 이미지
- train_labels는 학습에 사용되는 이미지의 레이블
- test_images는 테스트에 사용되는 이미지
- test_labels는 테스트에 사용되는 이미지의 레이블
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']학습 및 테스트 이미지를 확인할 때 사용하기 위해서 레이블을 리스트 형태로 "class_names" 에 담아준다.
2. 데이터 탐색

28 X 28 사이즈의 60,000장의 학습 이미지가 있는 것을 확인할 수 있다.

훈련 데이터의 레이블 역시 60,000개가 존재한다.

28 x 28 사이즈의 10,000장의 테스트 이미지가 있는 것을 확인할 수 있다.

테스트 레이블 역시 10,000개가 존재한다.
3. 데이터 전처리

이미지 픽셀의 가장 작은 값과 가장 큰 값을 확인 해보면, 0 ~ 255 인 것을 확인할 수 있다.

모델 학습을 진행하기 전에, 0~255 인 픽셀 값을 0~1로 조정한다고 한다. 이는 네트워크가 일을 처리하기 쉽도록 하는 일 이다. 0~255인 값을 넣었을 때보다 0~1값을 넣었을 때, 네트워크가 일하기 편해지고 결과도 좋게 나온다니 진행하는 것이 좋겠다.

간단하게 모든 픽셀 값을 가장 큰 수인 255로 나눠주어 normalization을 진행하고, 확인한다.
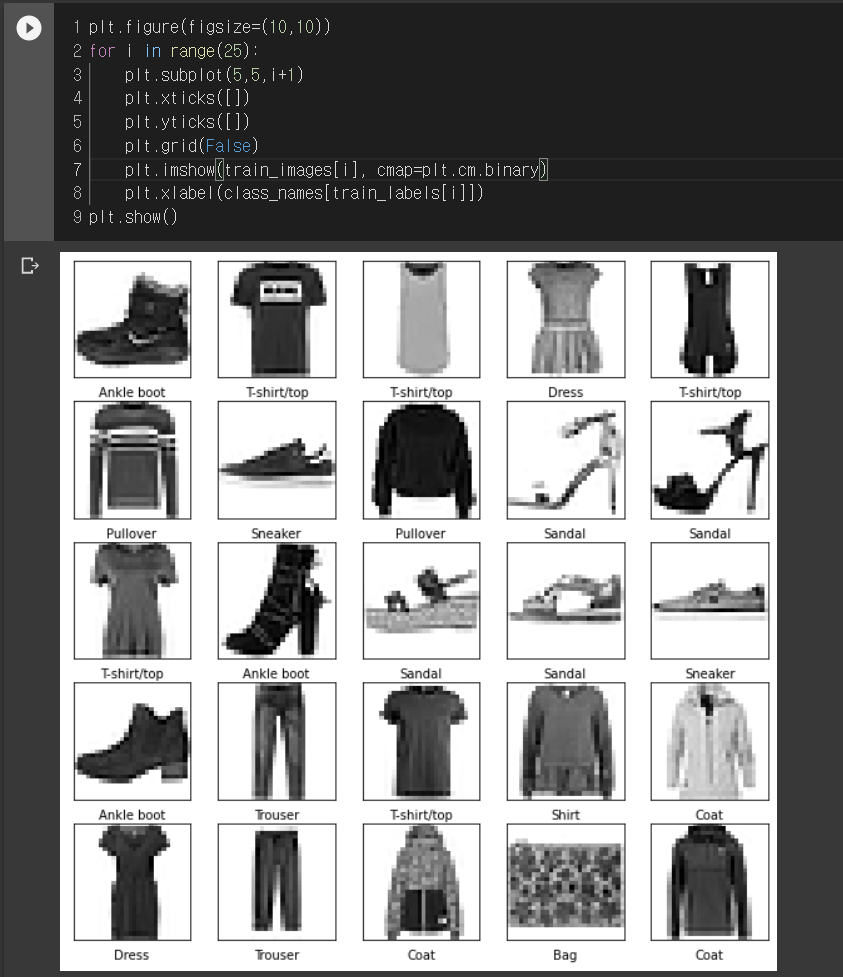
훈련 데이터에서 처음 25개 이미지와 레이블을 확인 해보도록 한다.
4. 모델 구성
a) 층 설정
- 이제는 본격적으로 모델의 레이어를 쌓고, 레이어들을 연결 시켜보도록 한다.
- 기본적으로 Sequential 레이어를 쌓고, 그 안에 Dense 레이어들을 아래와 같이 쌓도록 한다.
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])- Sequential 안에 첫 번째로 보이는 tf.keras.layers.Flatten()은 2차원 배열의 (28x28) 이미지 형태를 28x28 = 784픽셀의 1차원 배열의 형태로 변환하는 역할을 수행한다.
- tf.keras.layers.Dense() 층을 연속해서 쌓게 되는데, 첫 번째 Dense 층은 128개의 노드를 갖고 있다. 두 번째 또는 마지막 층은 10개의 노드를 갖고 있는데, 이는 마지막에 10개의 클래스에 관련된 각각의 확률을 반환하고 이로 해당하는 클래스를 추출한다. 10개의 확률을 모두 합하면 1이 된다.
b) 모델 컴파일
- 만든 모델을 컴파일 해야 학습을 진행할 수 있다.
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])- 컴파일에는 옵티마이저, 손실 함수 그리고 메트릭이 있다.
- 옵티마이저 : 모델이 예측하는 데이터와 손실 함수를 바탕으로 모델을 업데이트 하는 방식이다
- 손실 함수 : 훈련 중에 모델이 얼마나 정확한지 측정한다. 모델이 올바르게 학습되려면 손실 함수를 최소화 시켜야한다.
- 메트릭 : 훈련/테스트를 모니터링 하는데 사용되는 카테고리를 말한다.

- model.summary() 를 사용하면 만들 모델의 내용들을 확인할 수 있다.
모델 훈련
- 모델 훈련을 시작할 때는 model.fit() 메서드를 호출하여 시작한다.
a) 모델 피트

b) 정확도 평가

- 테스트를 진행한 정확도가 학습했을 때의 정확도 보다 조금 낮은데, 이는 과대적합 (overfitting) 때문이다.
- 과대적합: 머신러닝 모델이 훈련 데이터보다 새로운 데이터에서 성능이 낮아지는 현상을 말한다.
오늘 빅데이터기사 필기 시험을 등록했다. 텐서플로우 자격증은 언제든지 취득할 수 있으니, 시험을 치고 다시 돌아와서 해보도록 하겠다.
빅데이터 기사 필기 시험 공부도 중요한 내용 그리고 배우는 내용들은 계속해서 포스팅 할 생각이다.